Beyond Vector Similarity
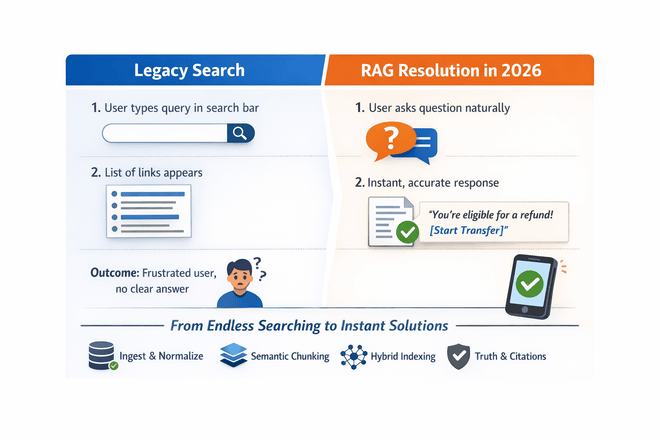
If you're still just doing "top-k vector search + LLM," you're building RAG like it's 2023. A modern RAG architecture is a multi-stage pipeline designed for precision, scale, and truth.
"The best LLM in the world can't fix a bad context window."
— CTO, TechStream TechnologiesStep-by-Step: Preparing Data for RAG
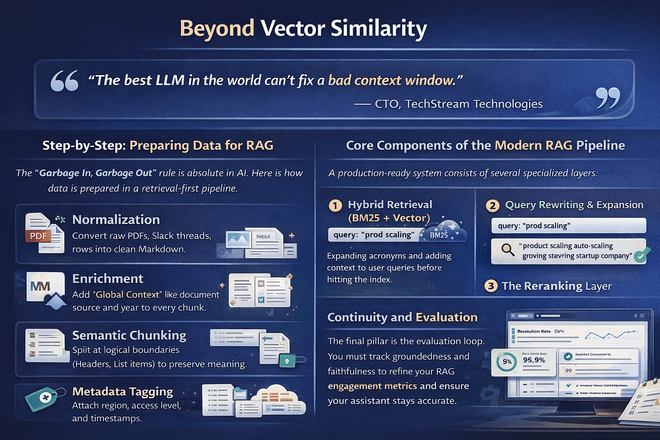
The "Garbage In, Garbage Out" rule is absolute in AI. Here is how data is prepared in a retrieval-first pipeline.
Core Components of the Modern RAG Pipeline
A production-ready system consists of several specialized layers:
1. Hybrid Retrieval (BM25 + Vector)
Combining the semantic power of embeddings with the lexical precision of BM25 keyword search.
2. Query Rewriting & Expansion
Expanding acronyms and adding context to user queries before hitting the index.
3. The Reranking Layer
Using cross-encoders to ensure the top chunks are actually the most relevant.
Continuity and Evaluation
The final pillar is the evaluation loop. You must track groundedness and faithfulness to refine your RAG engagement metrics and ensure your assistant stays accurate.

Leave a Comment